|
Verfasst am 27.09.2021 17:10:00 Uhr
Jeder Umzug ist wie Neuanfang Teil 64
Heute muss mal wieder ein neuer Tagebuchbericht mit folgendem Untertitel verfasst werden:
Das Drama mit der Aussprache von arabischen Texten:
Es gibt für arabische Schriftzeichen Transliterationen in lateinische Buchstaben. Doch manche sind wohl eher für den Komputer geeignet als für die menschliche Aussprache.Bei translate.google gibt es eine Latein-Umschrift, bei der man immer noch verzweifeln kann, wenn man zur Google-Transliteration / Transkription sich den Text mit dem Lautsprechersymbol vorlesen lässt. Der Grund für die Verzweifelung wird im 6.Nachtrag verständlich (⩠ =^= ⩠).
Auch ist es zum Verzweifeln, dasss translate.google nach so vielen Jahren der automatischen Übersetzungspraxis heute (06.02.2022) immer noch nicht "penultimate syllable" und "antepenultimate syllable" unterscheiden kann (s.Lit. über Betonung v. arabischen Wörtern). Beidemale übersetzt er es mit "vorletzte Silbe", obwohl "ante" die Vokabel "davor" und damit "antepenultimate syllable" die "vorvorletzte Silbe", also die 3.letzte Silbe bedeutet, falls die "vorletzte Silbe" die "2.letzte Silbe" ist. Was nützt mir das Wissen über die Betonung, wenn ich nicht die Vokalisierung kenne? - Frage: Auf welchen Klangkörper soll ich draufhauen? - Antwort: Hau drauf, Hauptsache laut!
Nun habe ich eine Webseite gefunden, die arabische Musterwörter der maschinenlesbaren SAMPA-LautUmschrift zuordnet. Eigentlich suche ich ja nach IPA-Beispielen (kleine Lateinbuchstaben und Doppelpunkt sind in SAMPA und IPA identisch, statt Vokal + ":" wie z.B. (a:, i:, u:) findet man auch Vokal mit Querstrich "Makron" darüber (ā, ī, ū), wobei mir die IPA-Zulassung unklar ist ; die Zeichen {":", "?"} werden auch durch {"ː", "ʔ"} ausgedrückt), aber "let's start" (Hinweis: nachfolgende Tabelle kann später umstrukturiert werden....)
| Zeilen-Nr. | Spalte2 | Spalte3 | Spalte4 | Spalte5 | Spalte6 |
|---|---|---|---|---|---|
| (1.Spalte) | (2.Spalte) | (3.Spalte) | (4.Spalte) | (5.Spalte) | (6.Spalte) |
| Freiraum für Anmerkungen: ... Pardon! die Titel für die Spalten überlege ich mir auch später ...
Bei Änderungswunsch der Tabelle bitte TB_2023-11-26 beachten ، = arabisches Komma ، siehe Lit. https://en.wiktionary.org/wiki/%D8%8C | |||||
| ٰ = arabisches "superscript Alef"/ "dagger alif" (eng.) / ʾalif ḵanjariyya (W-arb.) / "Dolch-Alif" / "perpendikuläres Alif" / "Dolch-Alef" (dts.) ( ـٰ )
siehe Lit. https://de.wikipedia.org/wiki/Taschk%C4%ABl "Alif al-Khanjariya" oder das weggelassene alif (ـٰـ) ist eine arabische Form, die die Aussprache des "erweiterten Alif" mit seinem Ersatz belegt, wie im Wort/Namen "(der) Gnädigste"/"Rahman" =^= [+v]: ٱلرَّحْمَٰنُ oder Demonstrativpronomen "hier" (dts.) = "/hāḏā/" =^= [+v]: هٰذَا [♂/mask.] bzw. "/hāḏihī/" =^= [+v]: هٰذِهِ [♀/fem.] (arb.) 03.12.2023:translate.google spricht Vokabeln, falls sie als Substantiv / Nomen (= "asm", "aism" (G-arb.) = "اسم" (arb.); "(das) Substantiv" (dts.) = "aliasm" (G-arb.) = الاسم (arb.)) interpretiert werden, in der NOM.Sg.-Form (, also mit finalem "-un", was sich manchmal auch als "-on" anhört) aus (siehe 3.Spalte). 06.12.2023: zur Aussprache siehe auch Lit. https://en.wikipedia.org/wiki/Hejazi_Arabic_phonology 06.12.2023: zu Regeln der Substantiv-Morphologietypen A, B, C, D siehe Lit. https://ar.wikipedia.org/wiki/%D8%A7%D8%B3%D9%85_(%D9%86%D8%AD%D9%88) ("die Morphologie", "die Konjugation" = "altasrif" (G-arb.) =(G-Ausspr.:) "ät-tas-ri-fu" = التصريف) 06.12.2023: zu Adjektiven s.Lit. https://ar.wikipedia.org/wiki/%D9%86%D8%B9%D8%AA (unerledigt) | |||||
| [] | #1576; باب = ب ا ب | "Tür" (dts.)
[sprich [IPA]: " ba:b " = sprich [SAMPA:]: " ba:b " ⩠ : "bab" (G-arb.) = G-klang wie [einzeln:] "bäbo", [sukzessiv:] "bäbi", "bäbin" "al" + "b.." → "al'b.." ] | /b/ | /ba/
[s.unten "Paris"] | Konsonant, plosiv |
| [] | #1578; تسع = ت س ع | "neun", "9" (dts.)
[sprich [IPA]: " tisʕ " = sprich [Sampa:] " tis?` " ⩠ : "tise" (G-arb.) "al" + "t.." → "at't.." ] | /t/ | /taːʔ/ | Konsonant, plosiv |
| [] | #1577;
| (1) "Seite" [fem.sg.] (dts.),
(2) (wfw:) "Seite-mein" ⩠ "meine Seite" (dts.),
(3) "Seiten" [Pl.] (dts.)
(4) Zahl "zehn" (dts.), (4a) eins + zehn = "elf" (dts.), (4b) "zehn Seiten" (dts.), (4c) "elf Seiten" (dts.)
(5) schön(er) [mask.] (dts.),
(6a) schön(e) [fem.] (dts.), (6b) wunderschöne [Übertreibung, Superlativ] (dts.),
(7) Baum [Sg.,Kollektivform] (dts.)
(8) Bäume [Pl.,Kollektivform] (dts.; analog zu "Leute")
| /-a/ | /gefesseltes taː/
/taː marbuːta/ /تَاء مَرْبُوطَة/ geschrieben auf dem Bild von Buchstabe /haː/ wie: ه oder: ـه, steht nur wort-final, gehört nicht zu den 28 anerkannten Buchstaben; hat viele Bedeutungen: kennzeichnet ...
synonym zu final ه wo=: Ägypt., Sudan | Konsonant, divers |
| [] | #1583; دار = د ا ر | "Zuhause, Heim, Haus" (dts.)
[sprich [IPA]: " da:r " = sprich [persisch(?)-Sampa:] " da:r " ⩠ : "dar" (G-arb.) = (G-Ausspr.:) "dara", "darun" "al" + "daru" → "äd'dāru" ] | /d/ | /daːl/ | Konsonant, plosiv |
| [] | #1591; طابع = ط ا ب ع | "Briefmarke, Stempel" (dts.)
[sprich [IPA]: " ʈa:biʕ " = sprich [Sampa:] " t`a:bi?` " ⩠ : "tabie" (G-arb.) = G-klang wie "tobeon" "al" + "tˤ.." → "atˤ'tˤ.." ] | /tˤ/ | /tˤaːʔ/ | Konsonant, plosiv |
| [] | #1590; ضرب = ض ر ب | "er prügelt", "er schlägt" (=?=) "er schlug" (dts.)
[sprich [IPA]: "dˁ..." =?= " darab " = sprich [Sampa:] " ɖarab " ⩠ : "darb" (G-arb.) = G-klang wie "darabo" "al" + "dˤ.." → "adˤ'dˤ.." ] | /dˤ/
/ðˤ/ wo=: Irak & arab.Halbinsel /ɮˤ/ wo=: klass.Arb.[veralt.] | /dˤaːd/ | Konsonant, plosiv |
| [] | #1603; كبير = ك ب ي ر | "groß" (=?=) "alt" (dts.)
[sprich [IPA]: " kabi:r " = sprich [Sampa:] " kabi:r " ⩠ : "kabir" (G-arb.) = G-klang wie "käbirun" "al" + "k.." → "al'k.." ] | /k/ | /kaːf/
/kɑːf/ wo=: Kuwait & Golf-Arb. | Konsonant, plosiv |
| [] | #1580; جميل = ج م ي ل | "schön" (dts.)
[sprich [IPA]: " ʤami:l " = sprich [ägypt.-Sampa:] " ʤami:l " ⩠ : "jamil" (G-arb.) = G-klang wie "jamilun" "al" + "g.." → "al'g.." ] | /d͡ʒ/
/ɡ/ wo=: Ägypt. | /d͡ʒiːm/
/ɡiːm/ wo=: Ägypt. [s.unten "jamil"] | Konsonant, plosiv |
| [] | #1571; أكل = أ ك ل | "Nahrung, Futter, Lebensmittel" (dts.)
[sprich [IPA]: " ?akl " = sprich [Sampa:] " ?akl " ⩠ : "'akal" (G-arb.) = G-klang wie "akala" "al" + "ʔ.." → "al'ʔ.." ] | /ʔ/
/ʔa/ | /alif/ | Konsonant, plosiv |
| [] | #1575; bzw. #1609; = ا bzw. ى , z.B.:
|
| /an/, /in/, /un/
bzw. /aa/, /ii/, /uu/ | /alif/ /alef/ steht am Wortende von sogenannten "maskulinen (??), eingeschränkten, verkürzten Substantiven" [Morphologietyp A] steht, gefolgt vom Lautzeichen "Hamza" am Wortende, von sogenannten "maskulinen (??), erweiterten Substantiven" [Morphologietyp B] Übersetzungsfehler: "tausend Vokale" meint richtig: "Vokal Alif" | Suffix /an/ bzw. Final-Vokal /aa/ |
| [] | #1610; = ي , z.B.:
|
| /ī/?? bzw. /yīn/ ?? | /jaːʔ/
steht am Wortende von sogenanntem "unvollständigen, unvollkommenen, defektiven, arab. Substantiv [Morphologietyp C], das von einem ursprünglichen, unbetonten Vokal 'ya' (eng.)/ 'ja' (dts.) (und) der vorherige (Vokal ??) gebrochen wird, abstammt." (Übersetzung unklar ??) | Final-SemiVokal /ya/ (eng.)/ /ja/ (dts.)
bzw. Suffix /in/ |
| [] | #nnnn; (??)
= .... (??) , z.B.:
|
| ... ??? | /.../ ??
Substantiv ist "Eigenname" [Morphologietyp D, weil es nicht den Regeln von Morphologietypen A, B, C gehorcht | ... (??) |
| [] (siehe 44) | #1569;
ء = ء | ... ??
[sprich [IPA]: "..." (G-arb.) = G-klang wie "..." ] | /.../ | /"hamza"/
markiert final Substantive als sogenannte "erweiterten Substantive" [Morphologietyp B], falls ihm ein Alef voransteht | kein Buchstabe, nur Lautzeichen |
| [] (siehe 45) | #1573;
إ = إ |
... ??
[sprich [IPA]: " ?i... " = sprich [Sampa:] " ... " ⩠ : "..." (G-arb.) = G-klang wie "..." ] | /ʔi/ | /alif mit "hamza" unten/
/alif mit Tief-hamza/ | Konsonant, plosiv |
| [] | #1602; قلب = ق ل ب | "Herz" (dts.)
[sprich [IPA]: " qalb " = sprich [Sampa:] " qalb " ⩠ : "qalb" (G-arb.) = G-klang wie "kolbon" "al" + "q.." → "al'q.." ] | /q/ | /qaːf/ | Konsonant, plosiv |
| [] | #1576;
برس = ب ر س Arabische Schreibweise "Paris" und initialem "ba"-Laut ب ب und mit medialem´"i"/"y"-Laut ي ي (s.Lit. wiki ): باريس = ب ا ر ي س Persische Arab-Schreibweise "Paris" und initialem "pa"-Laut پ پ und mit anderem medialem´"i"/"y"-Laut ی ی (s.Lit. wiki ): پاریس = پ ا ر ی س | "Paris" (=?=) "drücken Sie" (dts.)
[sprich [IPA]: " paris " = sprich [Lehnwort-Sampa:] " paris " ⩠ : "bris" (G-arb.) = G-klang wie "barison" ] | /b/ | /baːʔ/
[s.oben "Tür"] | Konsonant, plosiv für P in Fremdwörtern kann im Arabischen auch das persische "pe" = ﭗ ﭗ verwendet werden |
| [] | #1601;
فيل = ف ي ل | "Elefant" (dts.)
[sprich [IPA]: " fi:l " = sprich [Sampa:] " fi:l " ⩠ : "fil" (G-arb.) = G-klang wie "fiel" (dts.) "al" + "f.." → "al'f.." ] | /f/ | /faːʔ/
[s.unten "Nevien"] | Konsonant, frikativ |
| [] | #1601; نفين = ن ف ي ن | Eigenname "Nevien" (dts.)
[sprich [IPA]: " nivi:n " = sprich [Sampa:] " nivi:n " ⩠ : "nfin" (G-arb.) = G-klang wie "na'fejnu" ] | /f/ | /faːʔ/
[s.oben "Elefant"] | Konsonant, frikativ |
| [] | #1700;
ڤيل = ڤ ي ل | erweitertes arabisches Alfabet; "..." (dts.)
|
| /vaːʔ/ usw.
[s.oben "Elefant", "Nevien"] | Konsonant,
|
| [] | #1579; ثلاث = ث ل ا ث | "drei", "3" (dts.)
[sprich [IPA]: " θala:θ " = sprich [Sampa:] " Tala:T " ⩠ : "thalath" (G-arb.) = G-klang wie "thäläthun" "al" + "θ.." → "aθ'θ.." ] | /θ/ | /θaːʔ/ | Konsonant, frikativ |
| [] | #1584; ذكر = ذ ك ر | "männlich" (dts.)
[sprich [IPA]: " ðakar " = sprich [Sampa:] " Dakar " ⩠ : "dhukir" (G-arb.) = G-klang wie "dhakira" "al" + "ð.." → "að'ð.." ] | /ð/ | /ðaːl/ | Konsonant, frikativ |
| [] | #1592; ظلام = ظ ل ا م | "Dunkelheit" (dts.)
[sprich [IPA]: " ðˤala:m " = sprich [Sampa:] " D`ala:m " ⩠ : "zalam" (G-arb.) = G-klang wie "tholämon" "al" + "ðˤ.." → "aðˤ'ðˤ.." ] | /ðˤ/ | /ðˤaːʔ/ | Konsonant, frikativ |
| [] | #1587; سعيد = س ع ي د | "froh", "glücklich" (dts.)
[sprich [IPA]: " saʕi:d " = sprich [Sampa:] " sa?`i:d " ⩠ : "saeid" (G-arb.) = G-klang wie "saidon" [vokal-ähnlich wie vietnam.Stadt "Saigon"] "al" + "s.." → "as's.." ] | /s/ | /siːn/ | Konsonant, frikativ |
| [] | #1586;
زميل = ز م ي ل | "Kollege" (=?=) "Kollegen" (dts.)
[sprich [IPA]: " zami:l " = sprich [Sampa:] " zami:l " ⩠ : "zamil" (G-arb.) = G-klang wie "samilun" "al" + "z.." → "az'z.." ] | /z/ | /zaːj/
/zajn/ | Konsonant, frikativ |
| [] | #1589; صغير = ص غ ي ر | "klein" (dts.)
[sprich [IPA]: = "sˁ..." =?= " sˤaɣi:r ", " ʂaɣi:r " = sprich [Sampa:] " s`aGi:r " ⩠ : "saghir" (G-arb.) = G-klang wie "sorhärun" "al" + "sˤ.." → "asˤ'sˤ.." ] | /sˤ/ | /sˤaːd/ | Konsonant, frikativ |
| [] | #1588; شمس = ش م س | "Sonne" (dts.)
[sprich [IPA]: " ʃams " = sprich [Sampa:] " Sams " ⩠ : "shams" (G-arb.) = G-klang wie "schams" [ähnlich wie "Schams-Tag" statt "Samstag" analog zu "schabat" statt "Sabat"] "al" + "ʃ.." → "aʃ'ʃ.." ] | /ʃ/ | /ʃiːn/ | Konsonant, frikativ |
| [] | #1580; جميل = ج م ي ل | "schön" (dts.)
[sprich [IPA]: " ʒami:l " = sprich [Sampa:] " Zami:l " ⩠ : "jamil" (G-arb.) = G-klang wie "jamilun" "al" + "d͡ʒ.." → "al'd͡ʒ.." ] | /d͡ʒ/
/j/ wo=: "wiktionary" | /d͡ʒiːm/
[s.oben "jamil"] | Konsonant, frikativ |
| [] | #1582; خطاب = خ ط ا ب | "Buchstabe", "Brief" (=?=) "Rede" (dts.)
[sprich [IPA]: " χiʈa:b " = sprich [Sampa:] " xit`a:b " ⩠ : "khitab" (G-arb.) = G-klang wie "chitobon" "al" + "x.." → "al'x.." ] | /x/
/χ/ | /xaːʔ/
/χaːʔ/ | Konsonant, frikativ |
| [] | #1594; غرب = غ ر ب | "west", "Westen" (dts.)
[sprich [IPA]: " ɣarb " = sprich [Sampa:] " Garb " ⩠ : "gharb" (G-arb.) = G-klang wie "rharbo" "al" + "ɣ.." → "al'ɣ.." ] | /ɣ/
/ʁ/ | /ɣajn/
/ʁajn/ | Konsonant, frikativ |
| [] | #1581; حلم = ح ل م | "Traum" (dts.)
[sprich [IPA]: " ħilm " = sprich [Sampa:] " X\ilm " ⩠ : "hulm" (G-arb.) = G-klang wie "chulmun" "al" + "ħ.." → "al'ħ.." ] | /ħ/ | /ħaːʔ/ | Konsonant, frikativ |
| [] | #1593; علم = ع ل م | "Flagge" (=?=) "Wissenschaft" (dts.)
[sprich [IPA]: " ʕalam " = sprich [Sampa:] " ?`alam ", ?\alam " ⩠ : "eilm" (G-arb.) = G-klang wie "ailmän" ... (Pause; unfertig) ... ] | /ʕ/ | /ʕajn/ | Konsonant, frikativ |
| [] | #1607; هواء = ه و ا ء | "Luft" (dts.)
[sprich [IPA]: " hawa:? " = sprich [Sampa:] " hawa:? " ⩠ : "hawa' " (G-arb.) = G-klang wie "häwa'o" "al" + "h.." → "al'h.." ] | /h/ | /haːʔ/ | Konsonant, frikativ |
| [] | #1605; مال = م ا ل | "Geld" (dts.)
[sprich [Sampa:] " ma:l " ⩠ : "mal" (G-arb.) = G-klang wie "mälun" "al" + "m.." → "al'm.." ] | /m/ | /miːm/ | Konsonant, nasal |
| [] | #1606; نور = ن و ر | "hell", "leuchtend" (dts.)
[sprich [IPA]: " nu:r " = sprich [Sampa:] " nu:r " ⩠ : "nur" (G-arb.) = G-klang wie "nuru" "al" + "n.." → "an'n.." ] | /n/ | /nuːn/ | Konsonant, nasal |
| [] | #1585; رمال = ر م ا ل | "Sand" (dts.)
[sprich [IPA]: " rima:l " = sprich [Sampa:] " rima:l " ⩠ : "ramaal" (G-arb.) = G-klang wie "ri'mä'lun" "al" + "r.." → "ar'r.." ] | /r/ | /raːʔ/ | Konsonant, trill |
| [] | #1604;
لا initial-Ligatur #65275; ﻻ od.final-Ligatur #65276; ﻼ für: = ل ا | "nein", "nicht" (dts.)
[sprich [IPA]: " la: " = sprich [Sampa:] " la: " ⩠ : "la" (G-arb.) = G-klang wie "läa" ..لا ... (Pause; unfertig) ... ] | /l/ | /laːm/
[s.unten "Gott"] | Konsonant, lateral |
| [] | #1604; الله = ا ل ل ه | "Gott" (dts.)
[sprich [IPA]: " ?al'lah " = sprich [Sampa:] " ?al`l`ah " ⩠ : "allah" (G-arb.) = G-klang wie "älläa" ] | /ɫ/ | /ɫaːm/
[s.oben "nicht"] | Konsonant, lateral |
| [] | #1608; واحد = و ا ح د | "eins", "ein(er,e,es)" (dts.)
[sprich [IPA]: " wa:hid " = sprich [persisch(?)-Sampa:] " wa:hid " ⩠ : "wahig" (G-arb.) = G-klang wie "wua'chädon" "al" + "w.." → "al'w.." ] | /w/
/uː/ /u/ wo=: in Dialekt und Lehnworten /oː/ wo=: in Dialekt und Lehnworten | /waːw/ | Konsonant, semivokal |
| [] | #1610; يوم = ي و م | "Tag" (dts.)
[sprich [IPA]: " jawm " = sprich [persisch(?)-Sampa:] " jawm " ⩠ : "yawm" (G-arb.) = G-klang wie "jäo'mo" ... (Pause; unfertig) ... ] | /j/
/iː/ /i/ wo=: in Dialekt und Lehnworten /eː/ wo=: in Dialekt und Lehnworten | /jaːʔ/
[s.unten "Fest"] | Konsonant, semivokal |
| [] | #1575;
مال = م ا ل | "Geld" (dts.)
[sprich [IPA]: " ma:l " = sprich [lang-a-Sampa:] " ma:l " ⩠ : "mal" (G-arb.) = G-klang wie "mälun" ... (Pause; unfertig) ... ] | /ʔa/ | /ʔa.lif/ | Vokal /aː/ |
| [] | حل
= ح ل | "Lösung" (=?=) "Lösen" (dts.)
[sprich [IPA]: " ħal " = sprich [kurz-a-Sampa:] " X\al " ⩠ : "hala" (G-arb.) = G-klang wie helles "hallo" ... (Pause; unfertig) ... ] | l nach ðħ | kein Schriftzeichen | Vokal /a/ |
| [] (siehe 43) | عيد
= ع ي د | "Urlaub", "Fest", "Feier" (dts.)
[sprich [IPA]: " ʕi:d " = sprich [lang-i-Sampa:] " ?`i:d " ⩠ : "eid" (G-arb.) = G-klang wie "eidon" wie "Poseidon" ohne "pos" "al" + "iː.." → "al'iː.." ] | /j/
/iː/ /i/ wo=: in Dialekt und Lehnworten /eː/ wo=: in Dialekt und Lehnworten | /jaːʔ/
[s.oben "Tag"] | Vokal /eː/ |
| [] (siehe 42) | عيد
= ع ي د | "Urlaub", "Fest", "Feier" (dts.)
[sprich [IPA]: " ʕi:d " = sprich [lang-i-Sampa:] " ?`i:d " ⩠ : "eid" (G-arb.) = G-klang wie "eidon" wie "Poseidon" ohne "pos" "al" + "iː.." → "al'iː.." ] | /j/
/iː/ /i/ wo=: in Dialekt und Lehnworten /eː/ wo=: in Dialekt und Lehnworten | /jaːʔ/
[s.oben "Tag"] | Vokal /iː/ |
| [] (siehe 13) | #1569; ء = ء | ... ??
[sprich [IPA]: "..." (G-arb.) = G-klang wie "..." ] | /.../ | /"hamza"/ | kein Buchstabe, nur Lautzeichen |
| [] (siehe 14) | #1573; إ إتش إم إل = إ ت ش إ م إ ل | "H", "M", "L": =(ipa:) "haː", "ɛm", "ɛl" (dts.) =(ipa:) "eɪtʃ", "ɛm", "ɛl" (eng.) =(ipa:) "æɪtʃ", "ɛm", "ɛl" (AUS-eng.)
[sprich [IPA]: " ?i... " = sprich [Sampa:] " ... " ⩠ : "..." (G-arb.) = G-klang wie "..." ... (Pause; unfertig) ... ] | /ʔi/ | /alif mit "hamza" unten/
/alif mit Tief-"hamza"/ | Vokal /i/ |
| [] | #1575;#1569;
= اء = ا ء , z.B.:
|
| /aːʔ/ | /alif und "hamza" nachgestellt/
/alif plus "hamza"/ steht am Wortende von sogenannten "verlängerten Substantiven" [Morphologietyp B], d.h. Lehnwörtern aus Fremdsprachen Übersetzungsfehler: "tausend Vokale" meint richtig: "Vokal Alif" | langer Vokal /a:/ |
| [] | ظل
= ظ ل | "Schatten" (dts.)
[sprich [IPA]: " ðːil " = sprich [kurz-i-Sampa:] " D`il " ⩠ : "zala" (G-arb.) = G-klang wie "wala" wie frz. "voila" ... (Pause; unfertig) ... ] | l nach ðː | kein Schriftzeichen | Vokal /i/ |
| [] (siehe 49) | فول
= ف و ل | "Bohne" (dts.)
[sprich [IPA]: " fu:l " = sprich [lang-u-persisch(?)-Sampa:] " fu:l " ⩠ : "ful" [für Persisch nicht verfügbar] (G-arb.) = G-klang wie helles "fu'lu" "al" + "w.." → "al'w.." ] | /w/
/uː/ /u/ wo=: in Dialekt und Lehnworten /oː/ wo=: in Dialekt und Lehnworten | /waːw/ | Vokal /oː/ |
| [] (siehe 48) | فول
= ف و ل | "Bohne" (dts.)
[sprich [IPA]: " fu:l " = sprich [lang-u-persisch(?)-Sampa:] " fu:l " ⩠ : "ful" [für Persisch nicht verfügbar] (G-arb.) = G-klang wie helles "fu'lu" "al" + "w.." → "al'w.." ] | /w/
/uː/ /u/ wo=: in Dialekt und Lehnworten /oː/ wo=: in Dialekt und Lehnworten | /waːw/ | Vokal /uː/ |
| [] | عمر
= ع م ر | "Alter" (dts.)
[sprich [IPA]: " ʕumr " = sprich [kurz-u-Sampa:] " ?`umr " ⩠ : "eumar" (G-arb.) = G-klang wie helles "au'ma'ru" "al" + "w.." → "al'w.." ] | m nach ʕ | kein Schriftzeichen | Vokal /u/ |
(dp)(27.09.2021(3,5h))(28.09.2021(3,35h))(29.09.2021(5,75h))(06.10.2021(0,25h))(13.10.2021(0,5h))(28.01.2022(2,0h))(27.02.2022(8,85h))(05.05.2022(1,5h))(25.06.2022(0,5h))(26.06.2022(0,1h))(27.11.2023(1,35h))(28.11.2023(0,35h))(29.11.2023(0,5h))(03.12.2023(2,0h))(04.12.2023(0,5h))(05.12.2023(0,4h))(07.12.2023(0,25h))(09.12.2023(0,35h))(21.02.2024(0,25h))
1.Nachtrag am 28.9.2021 um 15:10Uhr
Nun möchte ich zu Testzwecken mal die G-arb-Lateinumschrift zu SAMPA und IPA gegenüberstellen:| هذه الصفحة جزء من مجموعة إطارات إتش تي إم إل.
= ه ذ ه ا ل ص ف ح ة ج ز ء م ن م ج م و ع ة إ ط ا ر ا ت إ ت ش ت ي إ م إ ل . | "Diese Seite ist Teil des HTML-Framesets " (dts.)
[sprich [IPA]: " hðh aːl sˤfħa ʒzh mn mʒmw(/u:)ʕa ʔ(/i, ʔi)tˤʔ(/ʔa)rʔ(/ʔa)t ʔ(/i, ʔi)tʃ tj(/iː) ʔ(/i, ʔi)m ʔ(/i, ʔi)l." PAUSE !!! = sprich [SAMPA:]: " hDh a:l s`fX\a ... " ⩠ : "hadhih al-safhat juz' min majmueat 'iitarat 'iitsh ti 'iim 'iil" (G-arb.) = G-klang wie "häðihi safhatu ʒus'un minn mäʒmuha:tu'itorrottin ätsch ti: ämm äll"] | gemischter Muster-Text |
- "haːðh" mit gedehntem "a": ه ا ذ ه = هاذه kann "hadhih", auch "hadhah" (G-arb) transliteriert werden und soll "dies ist" heissen
- "hðiːh" mit gedehntem "i": ه ذ ي ه = هذيه
- "hðh" ohne gedehnte Vokale: ه ذ ه = هذه kann für "diese Seite", "dies ist die Seite" verwendet werden
- in Wikipedia findet man: هٰذِهِ = ه ٰ ذ ِ ه ِ sei zu sprechen wie: "hādhihī" und für die 3 Fälle Nominativ Singular, Genitiv Singular, Akkusativ Singular gleich.
später mehr ...
- /haː.ði.hiː/,
- /haː.ði.hi/,
- /haː.ðih/
Die zugehörige maskuline Form ist ه ذ ا = هذا und wird von translate.google mit "hadha" (G-arb.) latinisiert. Und wieder geht ein Tag zu ende ...
später mehr ...
(dp)(28.09.2021(1,9h))(29.09.2021(2,2h))(12.10.2021(0,15h))(02.01.2022(0,5h))(06.02.2022(0,35h))
2.Nachtrag am 30.9.2021 um 07:10Uhr
Nachdem die Erkenntnis hilfreich ist, dass man in Wiktionary.org Aussprachemöglichkeiten zu Vokabeln finden kann, falls sie dort gelistet sind, nun zum nächsten Wort, die "Seite": [lese IPA:] "aːl sˤfħa" stimmt mit Wiktionary endlich mal fast überein: /sˤafħa/. In der 1.Silbe wird ein "a" dazugedichtet. Woher stammt diese Idee? Dort ist auch eine Deklinationstabelle für "Seite" (dts.) = "safha" (trk.;arb?) = (mit Vokalisierungs-Zusatzzeichen (unterstrichener Code): صَفْحَة = ص َ ف ْ ح َ ة = #1589; #1614; #1601; #1618; #1581; #1614; #1577;. Bei meiner Übersetzung hat diese "Kurzversion" gereicht: صفحة = ص ف ح ة = #1589; #1601; #1581; #1577;.Lernerschwerend ist, dass im IPA-Text "aːl" (/ "a:l") oder "al" für den Präfix steht, es aber nicht gesprochen wird. Der Konsonant nimmt die Lautung des initialen (ersten) Wortstamm-Konsonanten (in der 1.Silbe) an, hier also wird aus "die Seite" (dts.) =(G-arb.:) "alsafhatu" der (Google-Klang:) "as-safhatu" (Nominativ, Sg.). Diese vermutete Regel ist auch keine, weil dieses Phänomen sich zwar bei "der Mann" (dts.) bestätigt "ar-rajulu" (Nominativ,Sg.) statt geschriebenem (G-arb.:) "alrajulu", aber andere Nomen "der Garten" (dts.) =(G-Klang:) "alhadiqatu", geschrieben nur "alhadiqa" behalten die "al"-Aussprache bei. Hier besteht noch Klärungsbedarf! Muss ich mal alle Nomen mit alphabetisch unterschiedlichen Konsonanten durchprobieren: "die Tür" =(G-Klang:) "albabu" (Nominativ,Sg.) statt geschriebenem (G-arb.:) "albab", "die Neun" (dts.) =(Google-Klang:) "at-tisatu (Nominativ,Sg.) statt geschriebenem (G-arb.:) "altisea", "die Prügel" (dts.) =(Google-Klang:) "ad-darbu" (Nominativ,Sg.) statt geschriebenem (G-arb.:) "aldarba", "die Erinnerung" (dts.) =(Google-Klang:) "adh-dhikru" (Nominativ,Sg.) statt geschriebenem (G-arb.:) "aldhikr", usw. in die Tabelle eingearbeitet. Resümé:
der Buchstabe "l" vor einem sogenannten Zungenspitzen-Zahn-Laut verbleibt stumm. In Wikipedia wird dieser Zungenspitzen-Zahn-Laut auch "sun letter" (eng.) genannt (s.Lit.), im Gegensatz zum "moon letter" (eng.), vor welchem das "l" seine Aussprache behält.
Und ich grübele: falls die Araber solche Problem mit der "l"-Aussprache generieren können, dann dürften sie das deutsche Wort "also" nicht richtig sprechen können und lieber "daher" verwenden wollen? Auch die Handelsmarke "alna..." dürfte nicht richtig von Arabern ausgesprochen werden? Das müssten mal Sprachkurse testen!
Falls dieses Hauptwort "Seite" noch mit dem Demonstrativpronomen "diese" verknüpft wird, vermilzt die Aussprache von "hadhih" und "as'safhatu" weiter auf noch ungeklärte Weise.
Höre ich mir den arabisch-schriftlichen Text an, هذه الصفحة = ه ذ ه ا ل ص ف ح ة, so kann man mit gutem Gehör "hädihi..s-safhatu" (informale Lautschrift nach meiner Art) bzw. nach "wiki"-Art: "hāḏihī ṣ-ṣafḥatu" vernehmen (ohne Gewähr!). Wegen des Kongruenzgebots wird die Beugung des Demonstrativpronomens "hdh" an den Genus, Kasus, Numerus des Nomens "sayfa" angepasst.
(unfertig, irgendwann später mehr).
Und bevor ich mich in die Abschrift dieser Beugungstabelle stürze, muss ich ein paar Begriffe klären:
- es werden bei Wiktionary oder Wikipedia unsichtbare, nichtdruckbare Zeichen verwendet (an Worten angehangen), z.B.
- ‎ oder ‎ bedeutet "left-to-right" (eng.), entspricht Attribut dir="ltr" im SPAN oder DIV-Tag
- ‏ oder ‏ bedeutet "right-to-left" (eng.), entspricht Attribut dir="rtl" im SPAN oder DIV-Tag
- "Triptote" bezieht sich auf die Umlautungen in der Endsilbe bzgl. der Kasus-Formen Nominativ "u" (hier: "(t)u") wird zu "a" (hier: "(t)a") (Akkusativ) zu "i" (hier: "(t)i") (Genitiv) (S.Lit.)
später mehr ... - es gibt 3 Formen:
- "unbestimmte Form" (die Finalsilbe schließt mit "n" ab),
- "bestimmte Form" (mit präfigiertem Artikelzusatz "al" gebildet),
- "construct form" (eng.; bei Wiktionary) = Form für die/zur Verknüpfung mit Possessivpronomen / Personalpronomen (meist als Suffix), da auch im Deutschen "ein Haus", "das Haus", "sein Haus" drei unterschiedliche Wortformen sind. Am 05.11.2021 hab ich's am Beispiel meiner Wort-für-Wort-Übersetzung (mydoc106sum_arb2arb.small.html) begriffen. Am 03.10. schrieb ich hierzu noch: "soll etwas mit der Besitzergreifung der Nomen zu tun haben, d.h. damit sollen possessiv-Formen gebildet werden können, falls man es verstanden hat. Hab ich am 03.10.2021 abends noch nicht. Feierabend!"
Notizen:
كِتَاب
كتابي = ك ت ا ب ي = "kitāb-ī" (arb.; für alle Fälle) = "mein Buch" (dts.)
كتبي = ك ت ب ي = "kutub-ī" (arb.; für alle Fälle) = "meine Bücher" (dts.)
(unklar, keine Ahnung wofür)
- wozu wird neben dem NOM, GEN, AKK noch eine "informale Form" (eng2dts) kreiert?
Die richtige Übersetzung von "informal form" (eng.) ins Dts. ist "formlose" / "widrige" / "vereinfachte Form" (dts.). Die "informale" Schriftform ist quasi der Superlativ zu "less formal" (eng.) und unterscheidet nicht zwischen NOM, GEN und AKK, was die Deklinations-/Beugungs-Tabelle bei wiktionary für "Seite" zeigt und dem Arabisch-Schüler das Lernen erschwert. Die "vereinfachte Form" steht für alle drei genannten Fälle und mutiert daher zu einer Abkürzungsform bzw. Erinnerungs- und Gedächtnisstütze für Arabisch-Schrift- und -Sprachexperten. Angemerkt sei, dass andere grammatische Wortformen (z.B. Pronomen) ebenfalls der schriftlichen Vereinfachung unterliegen können.
Aus der dänisch-sprachigen Wikipedia erfährt man:die Kasusvokale werden wie die anderen kurzen Vokale im normalen Text nicht markiert (/ arabisch-schriftlich ausgeschrieben)Aus der englisch-sprachigen Wikipedia erfährt man:Die "Informale Aussprache" / der "Informale Kasus" (= "Informal short pronunciation" (eng.)) ist die Aussprache, die von Sprechern des modernen Standardarabischs in der spontanen Sprache verwendet wird (meine Ergänzung: evtl. auch in lateinschriftlichen google-Text (am 27.12.2021 ungeprüfte Vermutung)), d.h. beim Erstellen neuer Sätze, anstatt einfach einen vorbereiteten Text zu lesen. Es ähnelt der formalen kurzen Aussprache, außer:Darüber muss man mal lange Nachdenken.
dass die Regeln für das Weglassen von Schlussvokalen auch dann gelten, wenn ein clitischer Suffix hinzugefügt wird.
Grundsätzlich werden kurze Vokal- und Stimmungsenden nie ausgesprochen und es treten bestimmte andere Änderungen auf, die die entsprechenden umgangssprachlichen Aussprachen widerspiegeln.
Bei Wikipedia erfährt man: das Fachwort "nunation" bezieht sich auf den arabischen "n"-Laut, der dort "nun" heisst. Die Setzung eines zusätzlichen "n"'s an unbestimmte arabische Nomina wird im Hocharabischen "Nunation" bezeichnet. In allen modernen arabischen Dialekten sind die Kasusendungen und damit auch die Nunation verschwunden (Beleg fehlt)
Der Tag ist zu kurz.
später mehr ...
(dp)(30.09.2021(3,25h))(01.10.2021(2,85h))(02.10.2021(0,75h))(03.10.2021(3,35h))(04.10.2021(1,0h))(05.11.2021(0,35h))(27.12.2021(0,6h))
3.Nachtrag am 03.10.2021 um 19:54Uhr
Nachdem mir die englisch-sprachige Wikipedia nicht alle meine Fragen verständlich erklären konnte, bin ich mal fremdgegangen auf die französisch-sprachige Wikipedia-Seite und siehe da:die Vokabeln werden aus einigen tausend (meist 3-konsonantischen) Wortwurzeln erzeugt, und darauf können Variationsmuster / -schemata angewendet werden, die sowohl eine Beugung der Wortarten, eine Umwandlung zwischen Wortarten und eine dazu-gehörige gültige Vokalisierung erzeugen. Von diesen auch "Templates" (eng./dingl.) oder "Paradigmen" genannten Schematas soll es rund hundert Stück geben; ist doch für einen Sprachschüler bescheiden wenig, oder?
Es wird noch Monate, wenn nicht Jahre dauern, bis ich alle Templates für meine Übersetzung gefunden und begriffen habe.
(dp)(0,2h)
4.Nachtrag am 05.10.2021 um 18:46Uhr
Nachdem mir ein Buch über arabische Schrift besorgt habe, finde ich die Vokabel des bestimmten Nomen "das Alphabet" (dts.): الأبجدية = ا ل أ ب ج د ي ة und was hören meine Ohren von der netten google-Automatenstimme: "al'ab'jä'di'a'tu" oder in google-Lautschrift: "al'abjadiatu" (G-arb.) mit der Nominativ-Endung "-tu", die nicht immer gesprochen werden soll (denn geschrieben wurde sie nicht). Also gibt es ausser "a", "i", "u" auch ein "ä", wo ich nun noch nicht weiß, ob das ein kurzer "a"-Laut oder etwas anderes sein soll. Dieser "ä"-Laut folgt dem Zeichen (#1580;) mit Namen "ɡiːm", wessen Vokalität nicht ausgeschrieben / markiert / gekennzeichnet ist. Der Laut ist auch nicht dem Namen des ɡ-Zeichen entlehnt, denn dann hätte es sich wie ein "i" anhören müssen. Angemerkt sei, dass die Vokabel "ab'jädia" klanglich stark dem aus dem äthiopischen stammenden Begriff "Abugida" für ein silbenmäßig angeordnetes Alphabet ähnelt.Das sogenannte "hamza"-Zeichen (vokalisiert: هَمْزَة = unvokalisiert: همزة (arb.) = "hamza" (dts./eng.)), dass nicht nur über oder unter arabischen Buchstaben entdeckt werden kann, kann auch am Wortende stehen und den ungeübten Leser frustrieren, weil er es unter den Alphabet-Buchstaben nirgends findet. Und es fällt bei der Recherche auf: "hamza" kann sowohl als Nomen als auch als Adjektiv aufgefasst werden, ähnliche wie "schön" ein Adjektiv ist und "(das) Schöne" ein Nomen. Als Adjektiv ("Adjektiv", "Eigenschaftswort" (dts.) = "alnaeta", "alsifatu" (G-arb.) = (G-Ausspr.:) "än-na-tu", "äs-sifatu" = النعت, الصفة) hat es für maskulin und feminin die selben Beugungmuster bzw. Wortendungen. So etwas ähnliches kann einem auch bei der Vokabel "dukturah" blühen..., wo die Internet-Einträge auf einen Gebrauch als Nomen hindeuten, aber humane Bekannte behaupten, es sei ein Adjektiv.
In diesem Zusammenhang sei daran erinnert, dass unsere lateinschriftlichen waagrechten a-, o-, u-Doppelpünktchen ursprünglich die sütterlinschriftlichen Kleinzeichen für den Buchstaben "e" waren, so dass "ä" = "ae" ≙ "ae " ≙ "a" ", "ö" = "oe" ≙ "oe " ≙ "o" ", "ü" = "ue" ≙ "ue " ≙ "u" " verständlich werden.
In dem gleichen Buch finde ich an einer Stelle über "arabische Schrift" einen Nominalausdruck "die arabische Sprache" =(wfw:) "die Sprache arabisch" (dts.): اللغة العربية = ا ل ل غ ة ا ل ع ر ب ي ة und was hören meine Ohren von der netten google-Automatenstimme: "ä'lu'rä'tu'ara'bi'atu" (da muss man ganz konzentriert lauschen!) oder in google-Lautschrift: "allughat alearabia" (G-arb.). Man könnte "frei nach Goethe" auch "die Sprache des Arabischen" sagen, die Vokabel "arabisch" steht aber im Nominativ (Kongruenzregel verlangt gleichen Kasus wie das Nomen) und nicht im Genitiv (welcher im Arabischen fast immer nach Präpositionen benutzt wird). Das "u" nach "äl" und vor dem Reibelaut mit Namen "ʁajn" (#1594;) ist nicht ausgeschrieben und man wird es wohl als Kurzlaut autovervollständigen; ebenfalls das "ä" nach dem Reibelaut "ʁ". In diesem Kontext ist noch nicht verstanden, warum bei "das Alphabet" der Artikel wie "al", aber hier bei "die Sprache" der Artikel wie "äl" ausgesprochen wird. Hat dies mit der Doppel-"l"-Schreibung bei "aLLughat" zu tun? Wunder über Wunder ...
Kurz entschlossen ging ich heute zum arabischen Lebensmittelhändler, legte ihm ein arabischgeschriebenes Wort vor und bat ihn, er möge es vorlesen. Tat er nicht! Er nahm sein ..-phone heraus, scannte das Wort ab in die OCR-Texterkennung mit nachgeschaltetem google-Translator, dessen Automatenstimme mir dies vorlas. Wie hoch ist eigentlich die Analphabetenrate bei den Arabisch-Sprachigen?
(dp)(1,45h)(06.10.2021(0,5h))(17.02.2022(0,8h))(07.12.2023(0,25h))
5.Nachtrag am 06.10.2021 um 14:06Uhr
Nun lese ich weiter im Buch über arabische Schrift und finde endlich ein Beispiel einer Voll-Vokalisierung der arabischen Schrift mit Hilfe von Sonderzeichen (SZ.)- "fatha" / "fatḥa" / "fathah" (eng.) [=tiefer kurzer Vokal] / [ohne SZ. / unvokalisiert:] فتحة = ف ت ح ة [♀sg.(s.Lit.)] / [mit SZ. / vokalisiert:] فَتْحَة = ف َ ت ْ ح َ ة (Querstrich in der Diagonalen von rechts oben nach links fallend, über den Buchstaben gesetzt); es sei ein "instance noun" (eng.) zu "opening" (eng.) = "Verbalnomen" (dts.) zu "öffnen" (dts.; [vor Erstaunen geht einem der Mund auf: "a" wie in kurzem "ah!" / "ach!"]) = [vokalisiert:] فَتَحَ =[unvokalisiert:] فتح [=Verb] (arb.).
- "kasra" / "kasrah" (eng.) [=hoher vorne-artikulierter Vokal] / [unvokalisiert:] كسرة [♀sg.(s.Lit.)] (arb.) = [vokalisiert:] كَسْرَة (arb.) = ك َ س ْ ر َ ة (Querstrich in der Diagonalen von rechts oben nach links fallend, unter den Konsonant-Buchstaben gesetzt); es sei ein "instance noun" (eng.) zu "breaking" (eng.) = "Verbalnomen" (dts.) zu "unterbrechen" (dts.) = [vokalisiert:] كَسَرَ =[unvokalisiert:] كسر [=Verb] (arb.) und entspricht damit am ehesten dem "punktlosen trk. i" = "ı" oder aserbaidschanischen "ə".
- "damma" / "ḍamma" / "dhammah" [= gerundeter hinten-artikulierter Vokal] / [unvokalisiert:] ضمة [♀sg.(s.Lit.)] (arb.) = [vokalisiert:] ضَمَّة = ض َ م َ ّ ة (wie eine arabische Ziffer "Neun" mit dem Stamm in der Diagonalen von rechts oben nach links unten); es sei ein "instance noun" (eng.) zu "to embrace"; "to gather"; "to compress the lips" (eng.) = "Verbalnomen" (dts.; [vor Entsetzen geht einem der Mund mit gerundeten Lippen zu: "o" wie in kurzem "och!"]) zu "umarmen", "umrunden"; "sich versammeln"; "die Lippen komprimieren" (dts.) = [vokalisiert:] ضَمَّ =[unvokalisiert:] ضم [=Verb] (arb.); das kurze arb. "u" ist der einzige kurze Vokal im Arabischen, der mit Lippenrundung ausgesprochen wird.
- "sukun" / "sukūn" / "suku:n" / "sukuːn" / سُكُون = س ُ ك ُ و ن (Kreis wie Grad-Celsius-Zeichen über den Buchstaben gesetzt) und ...
- "schadda" / "šadda" / شَدَّة = ش َ د َ ّ ة (wie ein umgefallenes Epsilon in der Diagonale von rechts oben nach links liegend, auf den Buchstaben gesetzt).
- am Wortende über einen "Nichtbuchstaben hamza" gesetzt ... :
- erinnert ein "Kasra" (#1616; ◌ِ =(z.B. auf arab. "Hāʾ":) هِ) an das bestimmte Genitiv-Suffix "-i", welches ein bestimmtes Nomen kennzeichnet
- erinnern zwei "Kasra" / Doppelkasra / Kasratan / Kasratān (#1613; ◌ٍ =(z.B. auf arab. "Hāʾ":) هٍ) übereinander an das unbestimmte Genitiv-Suffix "-in" = "-i" + "-n" (Nunation), welches ein unbestimmtes Nomen kennzeichnet
- folgt ein "yāʾ" (#1610;) einer "kasra"-Kennzeichnung, wird aus dem kurzen "i" ein langes "i:"/"ī"
- am Wortende über einen "Nichtbuchstaben hamza" gesetzt ... :
- erinnert ein "Fatḥa" (#1614; ◌َ =(z.B. auf arab. "Hāʾ":) هَ) an das bestimmte Akkusativ-Suffix "-a", welches ein bestimmtes Nomen kennzeichnet
- erinnern zwei "Fatḥa" / Doppelfatha / Fathatan / Fathatān (#1611; ◌ً =(z.B. auf arab. "Hāʾ":) هً) übereinander an das unbestimmte Akkusativ-Suffix "-an" = "-a" + "-n" (Nunation), welches ein unbestimmtes Nomen kennzeichnet
- folgt ein "alif" (#1575;) oder "Alif maqsūra" ("reduziertes Alif"; isolierte Form #1609; od. #65263; Finalform: #65264;) einer "fatha"-Kennzeichnung, wird aus dem kurzen "a" ein langes "a:"/"ā"
- folgt ein "waw" (#1608;) einer "fatha"-Kennzeichnung, wird aus dem kurzen "a" ein Diphtong "au"
- folgt ein "yāʾ" (#1610;) einer "fatha"-Kennzeichnung, wird aus dem kurzen "a" ein Diphtong "ai"
- Am Wortende über einen "Nichtbuchstaben hamza" gesetzt ...:
- erinnert ein "Damma" (#1615; ◌ُ =(z.B. auf arab. "Hāʾ":) هُ) an das bestimmte Nominativ-Suffix "-u", welches ein bestimmtes Nomen kennzeichnet
- erinnern zwei "Damma" / Doppeldamma / Dammatan (#1612; ◌ٌ =(z.B. auf arab. "Hāʾ":) هٌ) nebeneinander an das unbestimmte Nominativ-Suffix "-un" = "-u" + "-n" (Nunation), welches ein unbestimmtes Nomen kennzeichnet
- ein "Damma" über dem Buchstaben, der einem "Waw" vorausgeht, erzeugt ein langes "u:"/"ū".
Das "Schadda" / "Šadda" / "Shaddah" (eng.) (#1617; ◌ّ =(z.B. auf arab. "Hāʾ":) هّ) erinnert daran, dass der so gekennzeichnete Konsonant lautlich verdoppelt auszusprechen sei. Falls ein Schadda genutzt wird, stehen die übrigen Vokalisierungszeichen z.B. bei "Fatha", "Damma" direkt über oder z.B. bei "Kasra" direkt unter dem Schadda. Das ist Theorie! In der Praxis finde ich bei meinem benutzten Fond, dass Shaddah + Kasrah nicht korrekt wiedergegeben wird, auch nicht bei Wikipedia (Stand:10.10.2021, https://en.wikipedia.org/wiki/Shadda#Combination_with_other_diacritics (1.Tabelle, Zeile 4:) "فَهِّمْ | fahhim | explain! | kasrah | Between the shaddah and the letter"):
علِّم
Es gibt fertige richtig entworfene "ARABIC LIGATURE SHADDA WITH KASRA" als
- Isolierte Form: #64610; ◌ﱢ
=(z.B. auf arab. "Hāʾ":) هﱢ
Eine Darstellung ...
- ... ist fehlerhaft bei z.B.: عُلﱢمَ
- ... sollte korrekt sein bei z.B.:
ﻋُﻠﱢﻢَ [mit #65250; als "finales mim"] oder: ﻋُﻠﱢمَ [mit #1605; als "finales mim"]
oder (mit andersfarblichen diakrit.Zeichen): ﻋُﻠﱢﻢَ [mit #65250; als "finales mim"] oder: ﻋُﻠﱢمَ [mit #1605; als "finales mim"]Anm.: Der Einfluss von diversen Browser(-Fonts) wurde nicht untersucht. Die Regel: "kasrah is between the shaddah and the letter" ist erfüllt (falls nicht, müsste es als fatha und shadda interpretiert werden).
Während in der fehlerhaften Darstellung der Arabisch-Basis-Block verwendet wird, und damit die (Browser)Software selber entscheidet, ob es ein initiales, mediales, finales oder separates Zeichen verwenden soll, muss man bei der korrekten Darstellung als Webseitengestallter selber für die richtige Auswahl der Buchstabenformen achten (hier wurde der Buchstabe "lam" als mediale oder mittlere Form gewählt: #65248;).
- und
Mediale Form: #64756; ◌ﳴ
z.B.: عُلﳴمَ
Darstellung = fehlerhaft; eine sinnvolle Verwendung ist unklar
- "ARABIC LIGATURE SHADDA WITH FATHA":
- Isolierte Form: #64610; ◌ﱠ
=(z.B. auf arab. "Hāʾ":) هﱠ
Eine Darstellung ...
- ... ist fehlerhaft bei z.B.: عُلﱠمَ
- ... sollte korrekt sein bei z.B.:
ﻋُﻠﱠﻢَ [mit #65250; als "finales mim"] oder: ﻋُﻠﱠمَ [mit #1605; als "finales mim"]
oder (mit andersfarblichen diakrit.Zeichen): ﻋُﻠﱠﻢَ [mit #65250; als "finales mim"] oder: ﻋُﻠﱠمَ [mit #1605; als "finales mim"]Anm.: Der Einfluss von diversen Browser(-Fonts) wurde nicht untersucht. Die Regel: "shaddah is between the fatha and the letter" ist erfüllt (falls nicht, müsste es als kasra und shadda interpretiert werden).
Während in der fehlerhaften Darstellung der Arabisch-Basis-Block verwendet wird, und damit die (Browser)Software selber entscheidet, ob es ein initiales, mediales, finales oder separates Zeichen verwenden soll, muss man bei der korrekten Darstellung als Webseitengestallter selber für die richtige Auswahl der Buchstabenformen achten (hier wurde der Buchstabe "lam" als mediale oder mittlere Form gewählt: #65248;).
- und
Mediale Form: #64754; ◌ﳲ
z.B.: عُلﳲمَ
Darstellung = fehlerhaft; eine sinnvolle Verwendung ist unklar
- Ebenfalls unbrauchbar ist die Verwendung von diakrit.Zeichen "fatha isolierte Form" aus dem UNIcode-Präsentations-Block B "#65142;" statt "#1614;":
ﻋُﻠﱠﻢﹶ [mit #65250; als "finales mim"] oder: ﻋُﻠﱠمﹶ [mit #1605; als "finales mim"]
oder: ﻋُﻠﱠﹶﻢ [mit #65250; als "finales mim"] oder: ﻋُﻠﱠﹶم [mit #1605; als "finales mim"]
- Isolierte Form: #64610; ◌ﱠ
=(z.B. auf arab. "Hāʾ":) هﱠ
Eine Darstellung ...
- "ARABIC LIGATURE SHADDA WITH DAMMA":
- Isolierte Form: #64609; ◌ﱡ
=(z.B. auf arab. "Hāʾ":) هﱡ
Eine Darstellung ...
- ... ist fehlerhaft bei z.B.: عُلﱡمَ
- ... sollte korrekt sein bei z.B.:
ﻋُﻠﱡﻢَ [mit #65250; als "finales mim"] oder: ﻋُﻠﱡمَ [mit #1605; als "finales mim"]
oder (mit andersfarblichen diakrit.Zeichen): ﻋُﻠﱡﻢَ [mit #65250; als "finales mim"] oder: ﻋُﻠﱡمَ [mit #1605; als "finales mim"]Anm.: Der Einfluss von diversen Browser(-Fonts) wurde nicht untersucht.
Während in der fehlerhaften Darstellung der Arabisch-Basis-Block verwendet wird, und damit die (Browser)Software selber entscheidet, ob es ein initiales, mediales, finales oder separates Zeichen verwenden soll, muss man bei der korrekten Darstellung als Webseitengestallter selber für die richtige Auswahl der Buchstabenformen achten (hier wurde der Buchstabe "lam" als mediale oder mittlere Form gewählt: #65248;).
- und
Mediale Form: #64755; ◌ﳳ
z.B.: عُلﳳمَ
Darstellung = fehlerhaft; eine sinnvolle Verwendung ist unklar
- Isolierte Form: #64609; ◌ﱡ
=(z.B. auf arab. "Hāʾ":) هﱡ
Eine Darstellung ...
- ... und viele andere Ligaturen mehr (s.Lit.: https://de.wikipedia.org/wiki/Unicodeblock_Arabische_Pr%C3%A4sentationsformen-A), die evtl. später ergänzt werden
der 1.Buchstabe des Paares soll ein "Suku:n" tragen und der 2.Buchstabe ein "Kasra", und dann würde wie von Geisterhand daraus ein Buchstabe, welcher "Kasra mit Shadda" trägt. Denkste:
z.B.: عُلِْمَ , عُلْلِمَ
Einzig eine PDF-Datei https://www.researchgate.net/publication/315379824_Design_and_Implementation_of_a_Diacritic_Arabic_Text-To-Speech_System gibt die diakritische Schrift richtig wieder.
Und nun die Überraschung fasst zum Schluss, nachdem ich etliche Stunden Zeit vergeudet habe:
die fehlerhafte Wiedergabe von "Schadda mit Kasra" (s.Lit. https://en.wikipedia.org/wiki/Shadda#Combination_with_other_diacritics (1.Tabelle, Zeile 4:)) liegt am Browser: fehlerhaft ist sie mit Edge, Firefox und Opera, korrekt ist sie mit Chrome und Safari (Stand: 12.10.2021, 16:22 Uhr )
| Browser | Screenshot |
|---|---|
| chrome | 
|
| edge | 
|
| firefox | 
|
| opera | 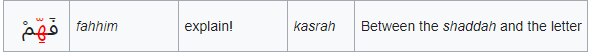
|
| safari | 
|
Falls also 1 arabischer Buchstabe nicht diakritisch sonderzeichenmarkiert ist, kann er mindestens in 8 Arten (=2x(3+1)) ausgesprochen werden: 3 mal einfachkonsonantisch mit kurzem Vokal und 3 mal doppelkonsonantisch mit kurzem Vokal. 1 mal einfachkonsonantisch ohne Vokal und 1 mal doppelkonsonantisch ohne Vokal: 8 Möglichkeiten = 21 x 41 = 81.
Bei der Kombination von 2 Buchstaben können sich 4 einfache mit 4 einfachen, 4 einfache mit 4 doppelten, 4 doppelte mit 4 doppelten und 4 doppelte mit 4 einfachen paaren: 64 Möglichkeiten = 22 x 42 = 82. Als Denkanstoss hier nur die Kombination von einfachkonsonantischem Zwei-Laut-Wortmuster:
mala, mali, malu, mal,
mila, mili, milu, mil,
mula, muli, mulu, mul,
mla, mli, mlu, ml
Zu diesen mathematischen kommen noch 48 = 4 x 12 (= 4 x 4 x 3) grammatische Kombinationen, nämlich die Kasusendungen zu Nom., Gen., Akk.:
mila, mili, milu, mil,
mula, muli, mulu, mul,
mla, mli, mlu, ml
malan, malin, malun,
milan, milin, milun,
mulan, mulin, mulun,
mlan, mlin, mlun
milan, milin, milun,
mulan, mulin, mulun,
mlan, mlin, mlun
Bei Wörtern aus 3 Buchstaben sind es "so Gott will" 23 x 43 = 83 = 512 mathematische Möglichkeiten.und zusätzlich 192 = 4 x 48 (= 4 x 4 x 12) grammatisch-mögliche Kombinationen, also insgesamt 704 Aussprachemöglichkeiten (siehe Beispiel-liste).
Und bei Wörtern aus 4 Buchstaben braucht man eigentlich schon ein eigenes Wörterbuch pro Wort: es gibt 84 = 4096 mathematische Möglichkeiten plus 768 = 4 x 192 (= 4 x 4 x 48) grammatisch-mögliche Kombinationen, also insgesamt 4864 Aussprachemöglichkeiten und unterschiedliche Wortbedeutungen, auch wenn ein Großteil davon Nonsens ist.
(dp)(4,0h)(07.10.2021(1,5h))(08.10.2021(0,5h))(10.10.2021(3h))(11.10.2021(3,5h))(30.11.2021(0,1h))(07.02.2022(0,2h))(09.02.2022(5,55h))(12.02.2022(0,75h))(13.02.2022(4,5h))
6.Nachtrag am 08.10.2021 um 14:26Uhr
Nun lese ich weiter im interessanten Internet und bin froh über die schriftliche Bestätigung meiner Vermutung durch die Fundstelle einer PDF-Datei: aus der nichtvokalisierten arabischen Schreibweise kann ein ungeübter Leser weder die Aussprache noch die Interpretation des Geschriebenen richtig wiedergeben. Es klingt nach einem Glückstreffer im Sprachlotto, wenn der arabischsprachig perfekte Leser behauptet, einen unvokalisierten arabischen Text richtig verstanden zu haben.Durch die orthographische Standarddarstellung der arabischen Schrift ist die Aussprache nicht eindeutig bestimmbar. Dies macht verständlich, dass der arabische Lebensmittelhändler sich diesen Text vom Automaten vorlesen lässt um zu entscheiden, ob dies für ihn die richtige Interpretation ist. Daher ist für die automatische Textverarbeitung die Diakritisierung des arabischen Textes notwendig!
In dieser PDF finde ich neue Bezeichnungen für schon Bekanntes: die diakritischen Zeichen "tanween fatha" (⩠ "fathatan") ⩠ "kurz.an"-SZ., "tanween damma" (⩠ "dammatan") ⩠ "kurz.in"-SZ., "tanween kasra" (⩠ "kasratan") ⩠ "kurz.un"-SZ., die nur auf dem finalen Konsonanten eines Wortes stehen, für unbestimmte Nomen benutzt werden, die Suffixe "-an", "-in", "-un" erzeugen und damit quasi Abkürzungs-Kennzeichen sind. Am 06.02.2022 ist klar, dass "tanween" für den arab.schriftlichen Fachbegriff "Nunation"-Kennzeichnung steht. Wieder ein Sprach-Rätsel gelöst!
Ich habe nicht Lust, mich über 512 Variationen zu einem 3-silbigen Wort zu amüsieren. Aber zum Verstehen der PDF-Datei mit ihrem arabisch-schriftlichen andersartigen Code muss ich möglichst diesen Code verstehen.
Hierzu sei die Lateinumschrift "G-arb." (für "google-arabisch") festgehalten, die ohne Sonderzeichen auskommt aber dafür manchmal zusätzlich enträtselt werden muss. (Siehe ein Link zur ausgelagerten riesigen Tabelle (Anlage))
Der "Rang innerhalb der PDF-Datei" wurde hinzugefügt, weil nicht klar ist, ob dahinter Willkür oder System steckt. Da für eine javascript-gesteuerte Sortierung (siehe Tipps dazu bei TB_2023-11-26) dem Autor momentan die Zeit fehlt, hier noch einmal die gleiche Tabelle (wie in der Anlage(??)) nach dem arabischen Alphabet sortiert:
| Rang (PDF): | 15 | 21 | 14 | 20 | 19 | 18 | 12 | 11 | 13 | 10 | 09 | 08 | 07 | 06 | 05 | 04 | 03 | 02 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Rang: | 00. | 01. | 01. a | 01. b | 01. c | 01. d | 02. | 03. | 03. a | 04. | 05. | 06. | 07. | 08. | 09. | 10. | 11. | 12. |
| Name: | ham za | alif | alif maq sū ra | alif mit Hoch- mad da oder ʔa.lif mad .da | alif mit Hoch- ham za | alif mit Tief- ham za | ba | taːʔ | ta mar buː ta | θaːʔ | d͡ʒiːm | ħaːʔ | xaːʔ | daːl | ðaːl | raːʔ | zaːj | siːn |
| G-arb.: | h oder ' | a | a | ʔaː oder a | ʔa oder 'a | ʔi oder 'i | b | t | t | th | j | h | kh | d | dh | r | z | s |
| arb.: | ء | ا | ى | آ | أ | إ | ب | ة | ت | ث | ج | ح | خ | د | ذ | ر | ز | س |
| Rang (PDF): | 01 | 36 | 35 | 34 | 33 | 32 | 31 | 30 | 29 | 28 | 26 | 25 | 24 | 23 | 22 | 16 | 27 | 17 |
| Rang: | 13. | 14. | 15. | 16. | 17. | 18. | 19. | 20. | 21. | 22. | 23. | 24. | 25. | 26. | 27. | 27. a | 28. | 28. a |
| Name: | ʃiːn | sˤaːd | dˤaːd | tˤaːʔ | ðˤaːʔ | ʕajn | ɣajn oder ʁajn | faːʔ oder fe | qaːf | kaːf | laːm | miːm | nuːn | haːʔ | waw | waw mit Hoch- ham za | jaːʔ | jaːʔ mit Hoch- ham za |
| G-arb.: | sh | s | d | t | z | e | gh | f | q | k | l | m | n | h | ʔuː oder w | ʔ oder ʔu oder w | y | ʔ oder y |
| arb.: | ش | ص | ض | ط | ظ | ع | غ | ف | ق | ك | ل | م | ن | ه | و | ؤ | ي | ئ |
Falls #57347; initial steht, wird die Reihenfolge der folgenden UNIcode-Paare vertauscht ausgeführt.
Für das Verständnis erschwerend kommt dazu, dass die arab.schriftliche Darstellung auf Seite 488 in der 10086.pdf-Datei grob vereinfacht auf "alan" (final-ن) kodiert ist, obwohl sie (visuell) als "alam" (final-م) mit den Augen lesbar ist und die Wiktionary-Einträge zu den zugehörigen englischen PDF-Übersetzungen auf "alam" (final-م) lauten.
Ausserdem ist der UniCode für den arab.Buchstaben "nun" = ن und das Zeichen kann auch visuell in der PDF-Datei so als "nun" bewundert werden. Aus der PDF-Datei wird aber der UNIcode ى ausgelesen, welches für Alif / Alef steht.
Vermutet wird ein arabischsprachlicher Kodierfehler in der PDF-Datei.
Für den Zweck der Recheche via lateinschriftliches Alphabet hier noch eine kurzgefasste Übersicht (Änderungen vorbehalten):
| G-arb.: | a | a | ʔaː oder a | ʔa oder 'a | b | d | d | dh | e | gh | f | h oder ' | h | h | ʔi oder 'i | j | k | kh | l | m | n | q | r | s | s | sh | t | t | t | th | ʔuː oder w | ʔ oder ʔu oder w | y | ʔ oder y | z | z |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| arb.: | ا | ى | آ | أ | ب | ض | د | ذ | ع | غ | ف | ء | ح | ه | إ | ج | ك | خ | ل | م | ن | ق | ر | ص | س | ش | ط | ة | ت | ث | و | ؤ | ي | ئ | ز | ظ |
Nach neuesten Erkenntnissen können Browser visuell die arabischen Schriftzeichen aus einer PDF-Datei zwar richtig darstellen, aber aus taktischen Gründen das Auslesen dieses Codes mehr oder weniger kryptisch verfälschen, so dass das Herauskopieren für den Nutzer nicht lohnenswert ist:
- arab. PDF-Code aus Mozilla - Firefox: “ عَلَن” = عَ - لَ - ن
- arab. PDF-Code aus Microsoft - edge: “ نَعل “ = نَ - ع - ل
Aber auch der Autor dieses Beitrages macht Fehler: am 07.+08.Feb.2022 lassen sich die 5-stelligen UNIcode-Zahlen nicht rekonstruieren, nachdem sein (De)Codier-Programm modernisiert worden ist (zur Problematik ein weiterführender Link). Durch die Browser wie "Firefox" und "Edge" und der "App" PDF24 (früher wurde "Apparat" durch das Akronym "App." abgekürzt, heutzutage bedeutet "App" eine Anwendung oder Applikation; wie die Zeiten sich ändern!) werden die richtigen 4-stelligen UniCodes der PDF-Datei benutzt. Das Programm Adobe Acrobat-Reader DC entzog sich dem Test durch Rechner-Absturz. Anschließend wurde es deinstalliert.
Gibt man ein vokalisiertes arab.schriftliches Wiktionary-Musterwort im Eingabefeld des (de)Codierprogrammes ein, so kann man im Testfeld
- A den vollständigen Unicode der vokalisierten Form und
- B den fehlerhaften Unicode der unvokalisierten Form oder der diakritischen Sonderzeichen aus, je nachdem ob 0 (+ n*2) oder 1 (+ n*2) Leerstelle(n) vor der vokalisierten Form im Eingabefeld steht (/stehen).
علم [=(v.l.n.r.:) #1593; #1604; #1605; ⩠ (im arb.Präsentations-UNIcode-Block B: (v.l.n.r.:) #65227; [+21=] #65248; [+2=] #65250; =:) ﻋﻠﻢ ⩠?=: #57347; [= Reihenfolgeumkehr statt dir="rtl"] + (v.l.n.r.:) #58338; [-2=] #58336; [-21=] #58315;] (= z.B.: "Flagge" (dts.))
Anm.: Nun (10.02.2022) ist die Ursache / Begründung für das Offset von "#6912;" zwischen den #5....-Codizes {#58338;, #58336;, #58315;} und den #6....-Codizes {#65250;, #65248;, #65227;} noch nicht verstanden.
Im Normalmodus gibt es diakritische (Vokalisierung-)Zeichen bei UNIcode #1614; (= "Hoch-Sz." "kurz.a"-"Fatha") #1616; (= "Tief-Sz." "kurz.i"-"Kasra") #1617; (=...) #1618; (= "Hoch-Sz." "vokallos"-"Sukkun") und #1614;#1617; (=...). Diesen soll(t)en Code-Werte #58100; #58102; #58103;(?) #58104; und #58185; entsprechen? Diesen entsprechen im arb.Ergänzungs- (/ Präsentations-)-UNIcode-Block keine Werte.
Und nun eine kleine unvollständige Auswahl von Worten mit diakritischer Vokalisierung zur Mustervokabel علم:
- aus Wiktionary:
علّم [= #1593; #1604;#1617; #1605 ⩠ ...] = /ʕallam/ [IPA] (arb.) = "er lehrte" / "er machte wissen(d)" [südlevantinisch.Dialekt; =aktiv, kausativ, abgeschlossene Handlung/Vergangenheit] (dts.) - عَلَم [= #1593; #1614; #1604; #1614; #1605; ⩠ #58338; #58100; #58336; #58100; #58315;] = /ʕa.lam/ [IPA] = /ʿalam/ [=unbest.+Konstru.Inform.Sg.] (wiki-arb.) = "Flagge", "Zeichen", "Symbol" (dts.)
- عَلَمَ [= #1593; #1614; #1604; #1614; #1605; #1614; ⩠ ...] = /ʿalama/ [=Konstru.Akk.Sg.] (wiki-arb.) = "Flagge", "Zeichen", "Symbol" [=Akk.Sg.] (dts.)
- عَلَمِ [= #1593; #1614; #1604; #1614; #1605; #1616; ⩠ ...] = /ʿalami/ [=Konstru.Gen.Sg.] (wiki-arb.) = "Flagge", "Zeichen", "Symbol" [=Gen.Sg.] (dts.)
- عَلَمُ [= #1593; #1614; #1604; #1614; #1605; #1615; ⩠ ...] = /ʿalamu/ [=Konstru.Nom.Sg.] (wiki-arb.) = "Flagge", "Zeichen", "Symbol" [=Nom.Sg.] (dts.)
- عَلَمٍ [= #1593; #1614; #1604; #1614; #1605; #1613; ⩠ ...] = /ʿalamin/ (wiki-arb.) = "(einer) Flagge", "(eines) Zeichens", "(eines) Symbols" [=unbest.Gen.Sg.] (dts.)
- عَلَمٌ [= #1593; #1614; #1604; #1614; #1605; #1612; ⩠ ...] = /ʿalamun/ (wiki-arb.) = "(eine) Flagge", "(ein) Zeichens", "(ein) Symbol" [=unbest.Nom.Sg.] (dts.)
- عَلِمَ [= #1593; #1614; #1604; #1616; #1605; #1614; ⩠ ...] = /ʿalima/ [IPA] (arb.) = "er wusste" [=aktiv; abgeschlossene Handlung/Vergangenheit] (dts.)
- aus Wiktionary:
عَلَّمَ [= #1593; #1614; #1604; #1614;#1617; #1605; #1614; ⩠ ...] = /ʕal.la.ma/ [IPA] (arb.) = "er lehrte" / "er machte wissen(d)" [=aktiv, kausativ, abgeschlossene Handlung/Vergangenheit] (dts.) - mit falschem Schriftbild (z.Zt. (11.02.2022) auch in Wiktionary):
عَلِّمْ [= #1593; #1614; #1604 #1616; #1617; #1605; #1618; ⩠ ...] = /ʿallim/ [IPA] (arb.) = "lehre er!", "lehre du(♂)!", "lehren Sie(♂Sg.)!" [=Imperativ] (dts.) - mit richtigem Schriftbild:
ﻋَﻠﱢﻢْ [= #65227; #1614; #65248; #64610; #65250; #1618; ⩠ ...] = /ʿallim/ [IPA] (arb.) = siehe oben
- mit falschem Schriftbild (z.Zt. (11.02.2022) auch in Wiktionary):
- عِلْم [= #1593; #1616; #1604; #1618; #1605; ⩠ ...] = /ʕilm/ [IPA] = /ʿilm/ [=unbest.+Konstru.Inform.Sg. = Verbalnomen von /ʿalima/] (wiki-arb.) = "Wissenschaft", "Information", "Kenntnis" (dts.)
- عِلْمَ [= #1593; #1616; #1604; #1618; #1605; #1614; ⩠ ...] = /ʿilma/ [=Konstru.Akk.Sg.] (wiki-arb.) = "Wissenschaft", "Information", "Kenntnis" [=Akk.Sg.] (dts.)
- عِلْمِ [= #1593; #1616; #1604; #1618; #1605; #1616; ⩠ ...] = /ʿilmi/ [=Konstru.Gen.Sg.] (wiki-arb.) = "Wissenschaft", "Information", "Kenntnis" [=Gen.Sg.] (dts.)
- عِلْمُ [= #1593; #1616; #1604; #1618; #1605; #1615; ⩠ ...] = /ʿilmu/ [=Konstru.Nom.Sg.] (wiki-arb.) = "Wissenschaft", "Information", "Kenntnis" [=Nom.Sg.] (dts.)
- عِلْمٍ [= #1593; #1616; #1604; #1618; #1605; #1613; ⩠ ...] = /ʿilmin/ (wiki-arb.) = "(einer) Wissenschaft", "(einer) Information", "(einer) Kenntnis" [=unbest.Gen.Sg.] (dts.)
- عِلْمٌ [= #1593; #1616; #1604; #1618; #1605; #1612; ⩠ ...] = /ʿilmun/ (wiki-arb.) = "(eine) Wissenschaft", "(eine) Information", "(eine) Kenntnis" [=unbest.Nom.Sg.] (dts.)
- عُلِمَ [= #1593; #1615; #1604; #1616; #1605; #1614; ⩠ ...] = /ʿulima/ [IPA] (arb.) = "er wurde informiert" (dts.)
- mit falschem Schriftbild (z.Zt. (11.02.2022) auch in Wiktionary):
عُلِّمَ [= #1593; #1615; #1604; #1616; #1617; #1605; #1614; ⩠ ...] = /ʿullima/ [IPA] (arb.) = s.unten - mit richtigem Schriftbild:
ﻋُﻠﱢﻢَ [= #65227; #1615; #65248; #64610; #65250; #1614; ⩠ ...] = /ʿullima/ [IPA] (arb.) = "er wurde trainiert", "er wurde belehrt" (dts.)
- mit falschem Schriftbild (z.Zt. (11.02.2022) auch in Wiktionary):
- aus der PDF-Datei:
عُلَّمَ [= #1593; #1615; #1604; #1617;#1614; #1605 #1614; ⩠ ...] = /ʿullama/ [IPA] (arb.) = "er lehrte" / "er machte wissen(d)"[unbekannt.Dialekt; =aktiv, kausativ, abgeschlossene Handlung/Vergangenheit] (dts.)
⩠ #58338; #58100;
Code-Beispiele werden später bereinigt und/oder mit neuem Inhalt versehen
In der Pdf-Datei heisst es sinngemäß, dass arabische Leser aus ihren sprachlichen Kenntnissen und dem Kontext die passenden diakritischen Zeichen im Geiste autovervollständigen. Nun soll aber ein Sprachschüler durch richtiges Lesen des Textes das Arabisch gleich richtig lernen. Also, wer autovervollständigt meine standardarabische-"Einfachst"-Schrift? Vielleicht nur ich selbst??? - Bin ja selber Schüler!
(dp)(3,5h)(10.10.2021(1,7h))(11.10.2021(0,8h))(12.10.2021(0,75h))(13.10.2021(0,5h))(07.02.2022(1,1h))(08.02.2022(4,155h)=wegen µs-Betriebsstörung)(09.02.2022(0,6h))(10.02.2022(1,5h))(11.02.2022(3,2h))(14.02.2022(1,6h))(15.02.2022(1,15h))(16.02.2022(2,75h))(18.02.2022(1,65h))(19.02.2022(1,8h))(28.11.2023(1,35h))
7.Nachtrag am 14.10.2021 um 09:48Uhr
Nun lese ich weiter im Pons-Lehrbuch über arabische Schrift und finde, dass Wörter, die "Alif auf Hamza" (#...;) enthalten, an dieser Stelle eigentlich eindeutig vokalisiert sind. Trotzdem ist es nützlich für Sprachanfänger, diese Stelle mit diakritischen Zeichen zusätzlich zu markieren, z.B. H, M, L: "eɪtʃ", "ɛm", "ɛl" (eng.) =("Alif über Hamza":) إتش إم إل →("Alif über Hamza über Kasra":) إِتش إِم إِل →("Alif über Hamza über Kasra" plus "Sukun":) إِتْشْ إِمْ إِلْUnd nun die Überraschung fasst zum Schluss:
nicht mehr überrascht bin ich über fehlerhafte Wiedergabe von farblich hervorgehobener Symbolik (Stand: 14.10.2021, 21:15 Uhr)
| Browser | (Fehl-)Verhalten: |
|---|---|
| Safari | vererbt nicht: die Farbigkeit von Alphabet-Buchstaben an "Sukun"
vererbt nicht: die Farbigkeit von "Alif über Hamza" an "Kasra" |
| Firefox | vererbt nicht: die Farbigkeit von Alphabet-Buchstaben an "Sukun"
vererbt die Farbigkeit von "Alif über Hamza" an "Kasra" |
| Chrome | vererbt die Farbigkeit von Alphabet-Buchstaben an "Sukun"
vererbt die Farbigkeit von "Alif über Hamza" an "Kasra" |
| Edge | vererbt die Farbigkeit von Alphabet-Buchstaben an "Sukun"
vererbt die Farbigkeit von "Alif über Hamza" an "Kasra" |
| Opera | vererbt die Farbigkeit von Alphabet-Buchstaben an "Sukun"
vererbt die Farbigkeit von "Alif über Hamza" an "Kasra" |
(dp)(2,2h)
8.Nachtrag am 20.10.2021 um 17:40Uhr
Nun lese ich weiter im Buske-Lehrbuch über arabische Grammatik ("die Grammatik" = "alnahw" (G-arb.) =(G-Ausspr.:) "än-nahu" = النحو) und finde, dass Wörter, die mit dem bestimmten Artikel "Alif" beginnen und in der Aussprache mit dem voranstehenden Wort verschmelzen, mit einem weiteren diakritischen Zeichen verziert werden können, vergleichbar mit dem französischen Apostroph zwischen "l" und "hospital", und dieses diakritische Zeichen heisst "Verbindungshamza" ("hamzatu [=Nom.] l-waṣli [=best.Gen.]" (arb.)) und ist bei Unicode-kodiert:- ٱ (#1649; ARABIC ALEF WASLA)
- ﭐ (#64336; ARABIC LETTER ALEF WASLA ISOLATED FORM)
- ﭑ (#64337; ARABIC LETTER ALEF WASLA FINAL FORM)
- [Translit.:] " ʾ̵ " [= rechter Halbkreis [#702; = für "Alif"] mit Macron/Makron [#821; = für "Wasla"]]
9.Nachtrag am 22.10.2021 um 21:07Uhr
Nun lese ich weiter in translate.google und finde eine Markierung, die bedeutet, dass eine Übersetzung von Nutzern als richtig markiert wurde. Ich wundere mich, das es heissen soll (1.Rätsel):- "auf französisch" (dts.) = "in French" (eng.) = "bialfaransia" (G-arb.) ⩠ "bi al'faransia" mit der echten arb. Präposition "bi"
- "auf deutsch" (dts.) = "in German" (eng.) = "fi almania" (G-arb.) ⩠ "fi 'almania" mit der arb. Präposition "fi";
warum nicht "bi al'almania" = "bialalmania"?
Und da schreibt das Langenscheidt'sche Arabisch-Wörterbuch, " ألرسالة " (arb.) = "ri'saːla" (arb.Langenscheidt) = "(al)risalat" (G-arb.) sei ein Synonym für "Thesis / (Doktor)Arbeit" (dts.) = "(al)'utruhat" = " الأطروحة ". Bei google bedeutet es aber nur "message" (eng.) = "Mitteilung" (dts.). Falls man "this is" (eng.) davor setzt, meint Google: "dies ist die inaugural-Dissertation" (dts.) = "hadha min alrisalat alaftitahiati." (G-arb.) = " هذا من الرسالة الافتتاحية. " (arb.) und man hört: "häðä minä'ri'säːlätil'äftitähiäti" (akustisch,google) und ich finde es konform zur Grammatik.
Zwei Möglichkeiten: entweder wird dieses "duktura..."-Nomen abartig gebeugt und es gibt dafür nur eine geheime google-Vorschrift oder es handelt sich um einen Druckfehler in irgendeiner Datenbank, auch einer Quelle, die google nicht gerne preisgibt. Ich vermute letztes: es können zwei Punkte auf dem Schluss-"h" fehlen und dann wäre die feminine Zugehörigkeit leichter erkennbar:
الدكتوراة statt الدكتوراه
Ungeklärte Rätsel! (dp)(0,15h)(23.10.2021(3,0h))(08.02.2022(9,25h))
archiviert (tbid____.___): (dp)(27.09.2021 (0,1h))